
Archivos de texto sin formato - en la mayoría de los casos los archivos con extensión txt - contienen información sólo de texto y no ofrecen una alternativa claramente definida para informar al ordenador el lenguaje que contienen. Lo más que OmegaT puede hacer en este caso, es asumir que el texto está escrito en el mismo idioma que utiliza el propio equipo. Esto no es problema para los archivos codificados en Unicode utilizando un conjunto de caracteres en codificación de 16 bits. Si el texto está codificado en 8 bits, sin embargo, puedes estar ante la siguiente situación incómoda: en lugar de mostrar el texto, para los caracteres Japoneses...
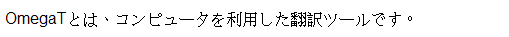
...El sistema lo mostrará así por ejemplo:
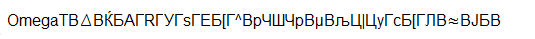
El equipo, corriendo OmegaT, tiene el Ruso como idioma predeterminado, y por lo tanto muestra los caracteres en el alfabeto Cirílico, y no en Kanji.
Básicamente, hay tres formas de abordar este problema en OmegaT. Todas ellas implican la aplicación de filtros de archivo en el menú Opciones .
abre tu archivo fuente en un editor de texto que interprete correctamente su codificación y guarda el archivo en codificación
"UTF-8"
. Cambia la extensión del archivo de .txt a .utf8.
OmegaT automáticamente debe interpretar el archivo como UTF-8. Esta es la alternativa con más sentido común, puesto que nos evita problemas a largo plazo.
- es decir, archivos con extensión .txt - : en la sección
Archivos de texto
del cuadro de diálogo Filtros de archivo, cambia la
Codificación de archivos fuente
de <auto> a la codificación que corresponde a tu archivo fuente .txt, por ejemplo, a .jp para el caso anterior.
por ejemplo, de .txt a .jp para los archivos de texto plano Japoneses: en la sección
Archivos de texto
del cuadro de diálogo Filtros de archivo, añade un nuevo
Patrón de nombre de archivo
(*.jp para este ejemplo) y selecciona los parámetros adecuados para la codificación de los archivos fuente y destino
OmegaT de manera predeterminada tiene la siguiente lista disponible para hacer facilitarte hacer frente a algunos archivos de texto plano:
archivos .txt automáticamente a ( <auto> ) interpretados por OmegaT como codificados en la codificación predeterminada del equipo.
Lo puedes comprobar tú mismo seleccionando el elemento
Filtros de archivo
en el menú
Opciones
. Por ejemplo, cuando tienes un archivo de texto en idioma Checo (muy probablemente escrito en el código
ISO-8859-2
) sólo tienes que cambiar la extensión.txt a .txt2 y OmegaT interpretará su contenido correctamente. Y, por supuesto, si deseas estar en el lado seguro, ten en cuenta la conversión de este tipo de archivo a Unicode, es decir, al formato de archivo .utf8.