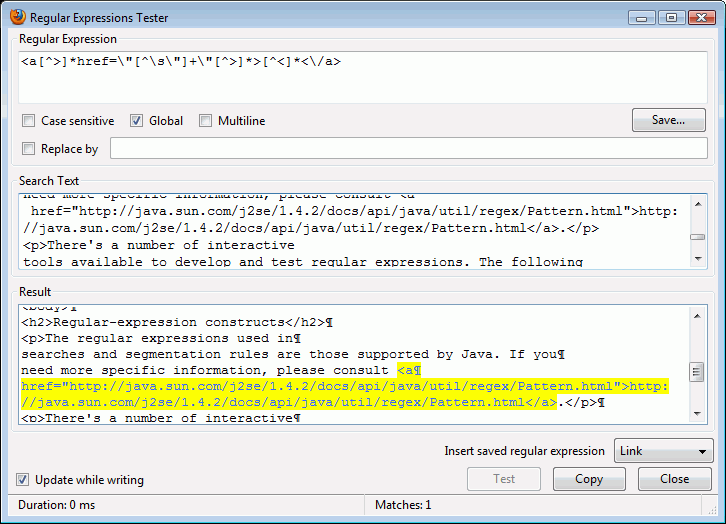
Οι κανονικές εκφράσεις (ή, εν συντομία, regex) που χρησιμοποιούνται για αναζητήσεις και στους κανόνες κατάτμησης, είναι εκείνες που υποστηρίζονται από τη Java. Αν χρειασθείτε πιο εξειδικευμένες λεπτομέρειες, συμβουλευθείτε την Τεκμηρίωση Java Regex. Βλέπε πρόσθετες βιβλιογραφίες και παραδείγματα, πιο κάτω.
Σημείωση
Αυτό το κεφάλαιο απευθύνεται σε προχωρημένους χρήστες που πρέπει να ορίσουν τις δικές τους ποικιλίες κανόνων κατάτμησης, ή να επινοήσουν πιο σύνθετους και ισχυρότερους όρους-κλειδί για την αναζήτηση.
Πίνακας 20. Regex - Flags
| Το construct |
... αντιστοιχίζει τα εξής |
| (?i) |
Επιτρέπει την αντιστοίχιση ανεξαρτήτως μικρών-κεφαλαίων γραμμάτων (case-insensitive). Από προεπιλογή, το μοτίβο είναι case-sensitive). |
Πίνακας 21. Regex - Χαρακτήρας
| Το construct |
... αντιστοιχίζει τα εξής |
| x |
Τον χαρακτήρα x, εκτός από τα παρακάτω... |
| \uhhhh |
Τον χαρακτήρα με δεκαεξαδική τιμή 0xhhhh |
| \t |
Τον χαρακτήρα tab ('\u0009') |
| \n |
Τον χαρακτήρα για νέα γραμμή (line feed) ('\u000A') |
| \r |
Τον χαρακτήρα για αλλαγή γραμμής/ carriage-return ('\u000D') |
| \f |
Τον χαρακτήρα για τροφοδότηση φόρμας/form-feed ('\u000C') |
| \a |
Τον χαρακτήρα alert (bell) ('\u0007') |
| \e |
Τον χαρακτήρα διαφυγής /escape ('\u001B') |
| \cx |
Τον χαρακτήρα ελέγχου που αντιστοιχεί στο x |
| \0n |
Τον χαρακτήρα με οκταδική τιμή 0n (0 <= n <= 7) |
| \0nn |
Τον χαρακτήρα με οκταδική τιμή 0nn (0 <= n <= 7) |
| \0mnn |
Τον χαρακτήρα με οκταδική τιμή 0mnn (0 <= m <= 3, 0 <= n <= 7) |
| \xhh |
Τον χαρακτήρα με δεκαεξαδική τιμή 0xhh |
Πίνακας 22. Regex - Quotation
| Το construct |
...αντιστοιχίζει τα εξής |
| \ |
Τίποτε, αλλά παραθέτει τον εξής χαρακτήρα. Αυτό απαιτείται αν θέλετε να εισάγετε οποιονδήποτε από τους μετα χαρακτήρες !$()*+.<>?[\]^{|} για να αντιστοιχίζονται ως οι εαυτοί τους. |
| \\ |
Για παράδειγμα, αυτός είναι ο χαρατκήρας backslash |
| \Q |
Τίποτε, αλλά παραθέτει όλους τους χαρακτήρες μέχρι το \E |
| \E |
Τίποτε, αλλά τελειώνει παραθέτοντας ότι άρχισε με το \Q |
Πίνακας 23. Regex - Κλάσεις για Unicode blocks και κατηγορίες
| Το construct |
...αντιστοιχίζει τα εξής |
| \p{InGreek} |
Έναν χαρακτήρα στο Greek block (απλό block) |
| \p{Lu} |
Ένα κεφαλαίο γράμμα (απλό category) |
| \p{Sc} |
'Ενα σύμβολο νομίσματος |
| \P{InGreek} |
Οποιονδήποτε χαρακτήρα εκτός από έναν που βρίσκεται στο Greek block (άρνηση) |
| [\p{L}&&[^\p{Lu}]] |
Οποιοδήποτε γράμμα εκτός από κεφαλαία γράμματα (αφαίρεση) |
Πίνακας 24. Regex - Κλασεις χαρακτήρων
| Το construct |
...αντιστοιχίζει τα εξής |
| [abc] |
a, b, ή c (απλή κλάση) |
| [^abc] |
Οποιονδήποτε χαρακτήρα εκτός από a, b, ή c (άρνηση) |
| [a-zA-Z] |
από το a μέχρι το z ή από το A μέχρι το Z, περιλαμβανομένου του (range) |
Πίνακας 25. Regex - Προκαθορισμένες κλάσεις χαρακτήρων
| Το construct |
...αντιστοιχίζει τα εξής |
| . |
Οποιονδήποτε χαρακτήρα (εκτός από line terminators) |
| \d |
Ένα ψηφίο: [0-9] |
| \D |
Ένα μη-ψηφίο: [^0-9] |
| \s |
Έναν χαρακτήρα κενού διαστήματος: [ \t\n\x0B\f\r] |
| \S |
Έναν χαρακτήρα μη-κενού διαστήματος: [^\s] |
| \w |
Έναν χαρακτήρα λέξη: [a-zA-Z_0-9] |
| \W |
Έναν χαρακτήρα μη-λέξη: [^\w] |
Πίνακας 26. Regex - Boundary matchers
| Το construct |
...αντιστοιχίζει τα εξής |
| ^ |
Η αρχή μιας γραμμής |
| $ |
Το τέλος μιας γραμμής |
| \b |
Ένα όριο μιας λέξης |
| \B |
Ένα όριο μιας μη-λέξης |
Πίνακας 27. Regex - 'Άπληστοι ποσοτικοποιητές' (greedy quantifiers)
| Το construct |
...αντιστοιχίζει τα εξής |
| X
?
|
X, άπαξ ή καθόλου |
| X
*
|
X, μηδέν ή περισσότερες φορές |
| X
+
|
X, μηδέν ή περισσότερες φορές |
Σημείωση
Οι 'άπληστοι ποσοτικοποιητές' (greedy quantifiers) θα αντιστοιχίσουν όσο περισσότερο μπορούν. Για παράδειγμα, το
a+?
θα αντιστοιχίσει το aaa στο
aaabbb
Πίνακας 28. Regex - Απρόθυμοι (Reluctant) 'μη-άπληστοι ποσοτικοποιητές'
| Το construct |
...αντιστοιχίζει τα εξής |
| X?? |
X, άπαξ ή καθόλου |
| X*? |
X, μηδέν ή περισσότερες φορές |
| X+? |
X, μηδέν ή περισσότερες φορές |
Σημείωση
Οι 'μη-άπληστοι ποσοτικοποιητές' θα αντιστοιχίσουν όσο λιγώτερο μπορούν. Για παράδειγμα, το
a+?
θα αντιστοιχίσει πρώτα το
a
στο
aaabbb
Πίνακας 29. Regex - Λογικοί τελεστές
| Το construct |
...αντιστοιχίζει τα εξής |
| XY |
X ακολουθούμενο από το Y |
| X|Y |
Είτε X ή Y |
| (XY) |
XY ως μια ενιαία ομάδα |