
OmegaT possède un vérificateur orthographique intégré basé sur le vérificateur d'orthographe utilisée dans Apache OpenOffice, LibreOffice, Firefox et Thunderbird. Il est donc en mesure d'utiliser la vaste gamme de dictionnaires orthographiques gratuits utilisés par ces applications.
Avant de pouvoir utiliser la fonction vérificateur orthographique, il est nécessaire d'installer un ou plusieurs dictionnaires (c.-à.-d. concernant votre langue cible). Pour installer les dictionnaires orthographiques, appliquez la procédure suivante :
Dans votre gestionnaire de fichiers, créez un nouveau dossier dans un endroit convenant au stockage des dictionnaires orthographiques (D:\Translations\spellcheckers pour l'exemple ci-dessous).
Dans OmegaT, sélectionnez , puis cliquez sur à côté du champ dossier des fichiers dictionnaire. Trouvez et sélectionnez le dossier de dictionnaires que vous avez préalablement créé.
Placez les fichiers dictionnaire de votre choix à l'intérieur de ce dossier. Il existe principalement deux façons de réaliser ceci. Vous pouvez soit copier les fichiers manuellement (depuis n'importe quel endroit de votre système) en utilisant votre gestionnaire de fichier ; soit utiliser la fonction d'OmegaT « Installer un nouveau dictionnaire... » qui vous fournit une liste des dictionnaires disponibles (il vous suffit alors de sélectionner celui qui vous convient). Remarquez que la fonction « Installer » requiert une connexion Internet. Les langues sélectionnées seront ainsi installées et pourront donc apparaître dans la fenêtre de configuration du vérificateur orthographique (cela peut prendre un certain temps).
Copier manuellement les fichiers est intéressant lorsque vous possédez déjà les fichiers dictionnaire adéquats sur votre ordinateur, par exemple, s'ils font partie d'une installation OpenOffice, LibreOffice, Firefox ou Thunderbird. Il est plus simple, cependant, de rechercher des dictionnaires en ligne, en utilisant le champ URL des dictionnaires en ligne :
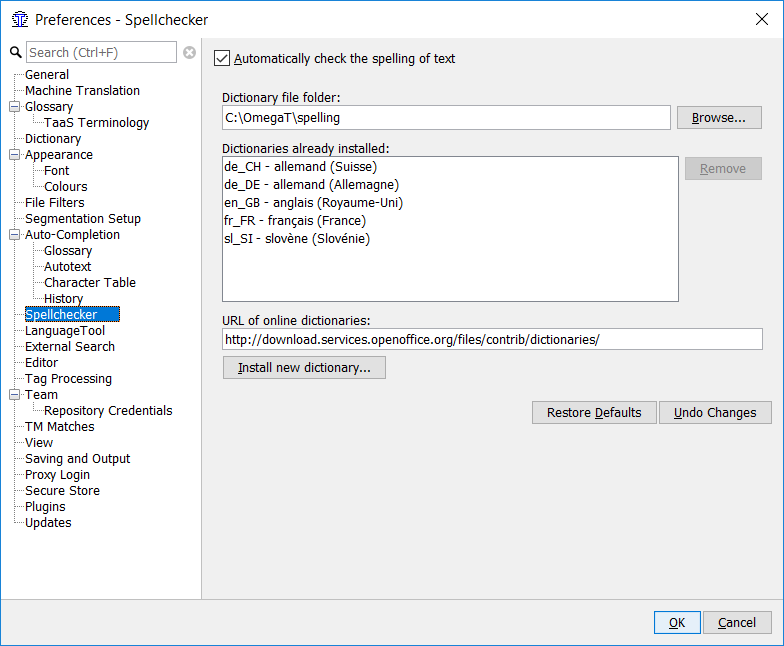
Cliquer sur le bouton permet d'ouvrir la fenêtre d'installation des dictionnaires dans laquelle vous pourrez sélectionner les dictionnaires que vous souhaitez installer.
Le nom des fichiers doit correspondre au code de langue de votre langue cible tel qu'il est défini dans la boite de dialogue des propriétés du projet (). Par exemple, si vous avez sélectionné ES-MX (Espagnol Mexicain) comme langue cible, les fichiers dictionnaire doivent être appelés es_MX.dic et es_MX.aff. Si vous ne disposez que d'un dictionnaire espagnol standard (ayant par exemple pour noms de fichier es_es.dic et es_es.aff), vous pouvez copier ces fichiers et les renommer es_MX.dic et es_MX.aff, et le dictionnaire orthographique fonctionnera. Remarquez que celui-ci fera des corrections correspondant évidemment bien plus à l'espagnol standard (Castillan) qu'à l'espagnol mexicain.
Il n'est pas nécessaire de préciser à OmegaT quel dictionnaire orthographique utiliser ; OmegaT utilisera automatiquement le bon dictionnaire en se basant sur les codes de langue de votre projet. Assurez-vous toutefois que les codes soient exactement les mêmes : un dictionnaire FR-FR ne fonctionnera pas si vous avez utilisé le code FR pour définir la langue cible. Si nécessaire, modifiez les noms de fichier des dictionnaires ou modifiez les paramètres qui concernent la langue du projet.
Pour mettre en fonction le vérificateur orthographique, sélectionnez et cochez la case Vérifier automatiquement l'orthographe (voir ci-dessus).
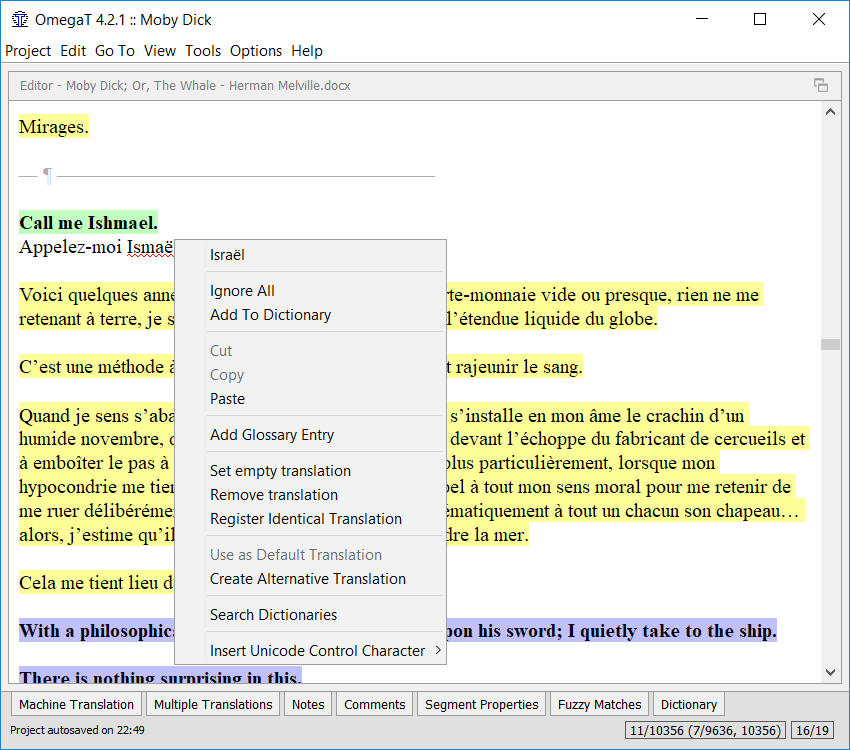
Un clic-droit sur un mot souligné (Artund dans l'image ci-dessus) ouvre un menu déroulant affichant une liste de suggestions pour la correction (Art und). Il est également possible de demander au correcteur orthographique d'ignorer toutes les occurrences du mot mal orthographié ou de l'ajouter au dictionnaire.
Si le vérificateur orthographique ne marche pas, assurez-vous d'abord que la case « Vérifier automatiquement l'orthographe » est cochée (.
Vérifiez également que le code de la langue cible de votre projet est conforme aux lexiques disponibles dans la fenêtre de configuration. Le vérificateur orthographique utilise le code de la langue cible pour déterminer quelle langue va être utilisée : si la langue cible est du portugais brésilien (PT_BR), le sous-dossier contenant les lexiques doit contenir les deux fichiers lexicaux appelés pt_br.aff et pt_br.dic .
Si après avoir déjà traduit une grande quantité de texte, vous vous apercevez que le code de langue de la langue cible de votre projet ne correspond pas à celui du vérificateur orthographique (vous avez pt_BR en langue cible, mais il n'existe aucun lexique pt_BR, par exemple), il suffit de copier les deux fichiers correspondant et de les renommer (ex. : passez de pt_PT.aff et pt_PT.dic à pt._BR.aff et pt_BR.dic ). Il est évidemment plus simple de s'arrêter un moment et de télécharger les versions correctes du vérificateur orthographique.
Remarquez que Supprimer supprime physiquement les lexiques sélectionnés. Si ces lexiques sont utilisés par d'autres applications de votre système, ils disparaîtront également de ces applications. Si, pour quelle que raison que ce soit, vous deviez le faire à un moment ou un autre, il pourrait être utile de copier les fichiers concernés dans un dossier différent, spécialement réservé à OmegaT.